Abstract
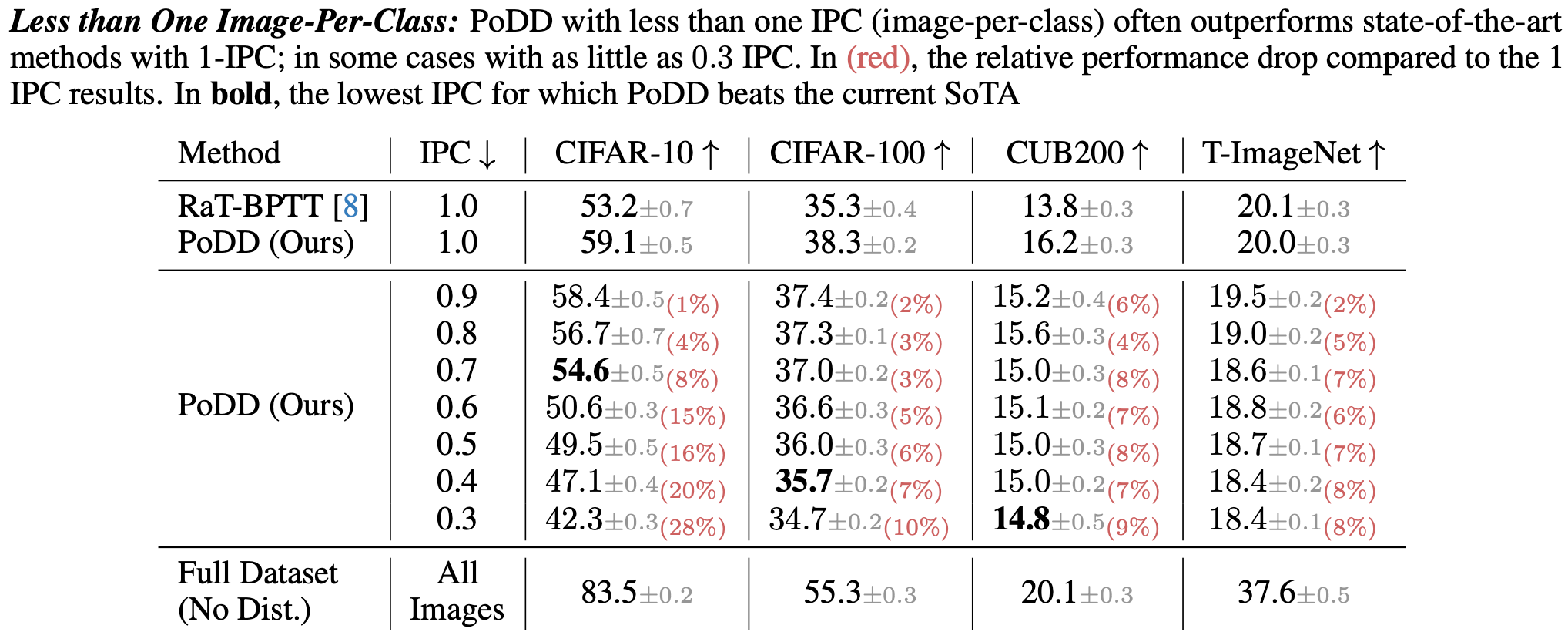
Dataset distillation aims to compress a dataset into a much smaller one so that a model trained on the distilled dataset achieves high accuracy. Current methods frame this as maximizing the distilled classification accuracy for a budget of K distilled images-per-class, where K is a positive integer. In this paper, we push the boundaries of dataset distillation, compressing the dataset into less than an image-per-class. It is important to realize that the meaningful quantity is not the number of distilled images-per-class but the number of distilled pixels-per-dataset. We therefore, propose Poster Dataset Distillation (PoDD), a new approach that distills the entire original dataset into a single poster. The poster approach motivates new technical solutions for creating training images and learnable labels. Our method can achieve comparable or better performance with less than an image-per-class compared to existing methods that use one image-per-class. Specifically, our method establishes a new state-of-the-art performance on CIFAR-10, CIFAR-100, and CUB200 using as little as 0.3 images-per-class.

Dataset Compression Scale
In this paper, we ask: "Can we distill a dataset into less than one image-per-class?" Existing dataset distillation methods are unable to do this as they synthesize one or more distinct images for each class. To this end, we propose Poster Dataset Distillation (PoDD), which distills an entire dataset into a single larger image, that we call a poster. The benefit of the poster representation is the ability to use patches that overlap between the classes. We find that a correctly distilled poster is sufficient for training a model with high accuracy.
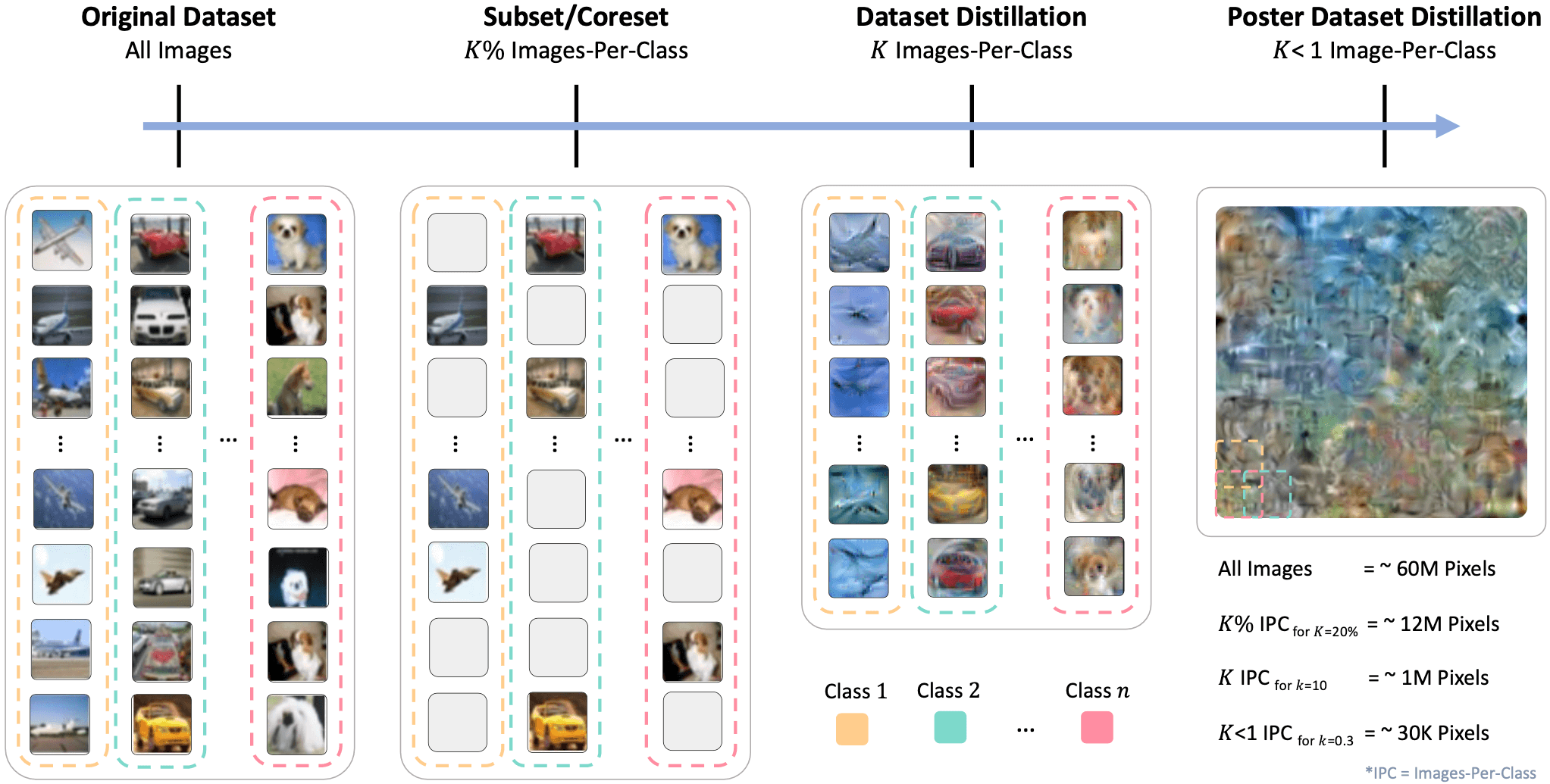 Dataset Compression Scale: We show increasingly more compressed methods from left to right. The original dataset contains all of the training data and does not perform any compression. Coreset methods select a subset of the original dataset, without modifying the images. Dataset distillation methods compress an entire dataset by synthesizing K images-per-class (IPC), where K is a positive integer. Our method (PoDD), distills an entire dataset into a single poster that achieves the same performance as 1 IPC while using as little as 0.3 IPC
Dataset Compression Scale: We show increasingly more compressed methods from left to right. The original dataset contains all of the training data and does not perform any compression. Coreset methods select a subset of the original dataset, without modifying the images. Dataset distillation methods compress an entire dataset by synthesizing K images-per-class (IPC), where K is a positive integer. Our method (PoDD), distills an entire dataset into a single poster that achieves the same performance as 1 IPC while using as little as 0.3 IPC
Poster Dataset Distillation Overview
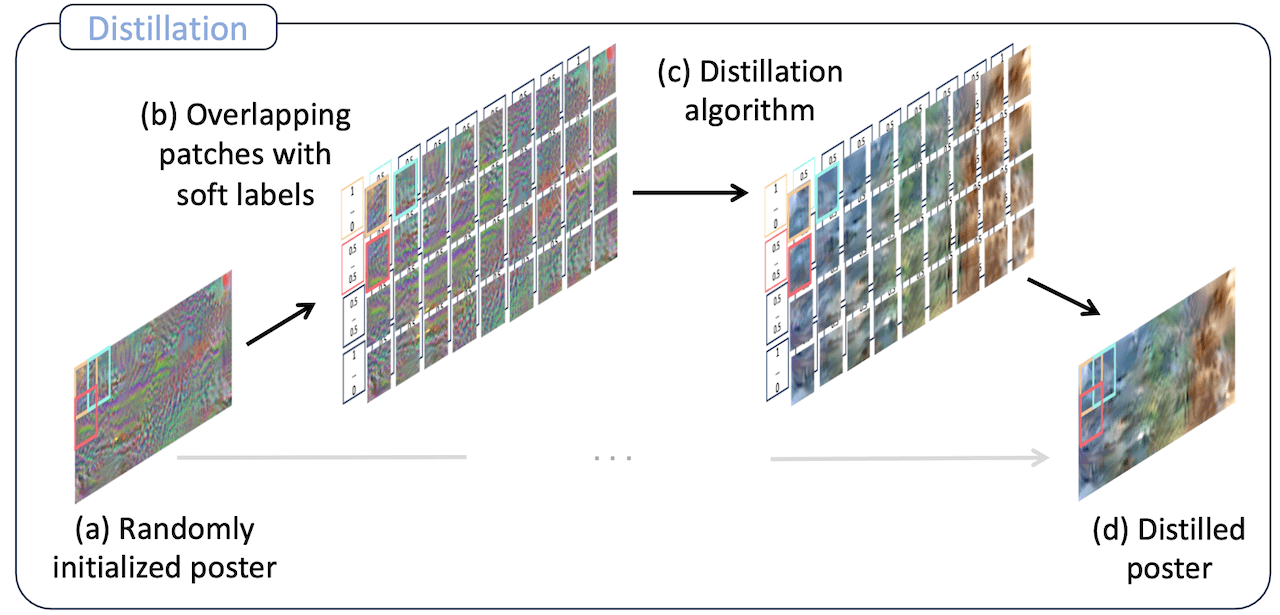
We start by initializing a random poster (a), during distillation, we optimize overlapping patches and soft labels (b-c). The final distilled poster has fewer pixels than the combined pixels of the individual images (d)
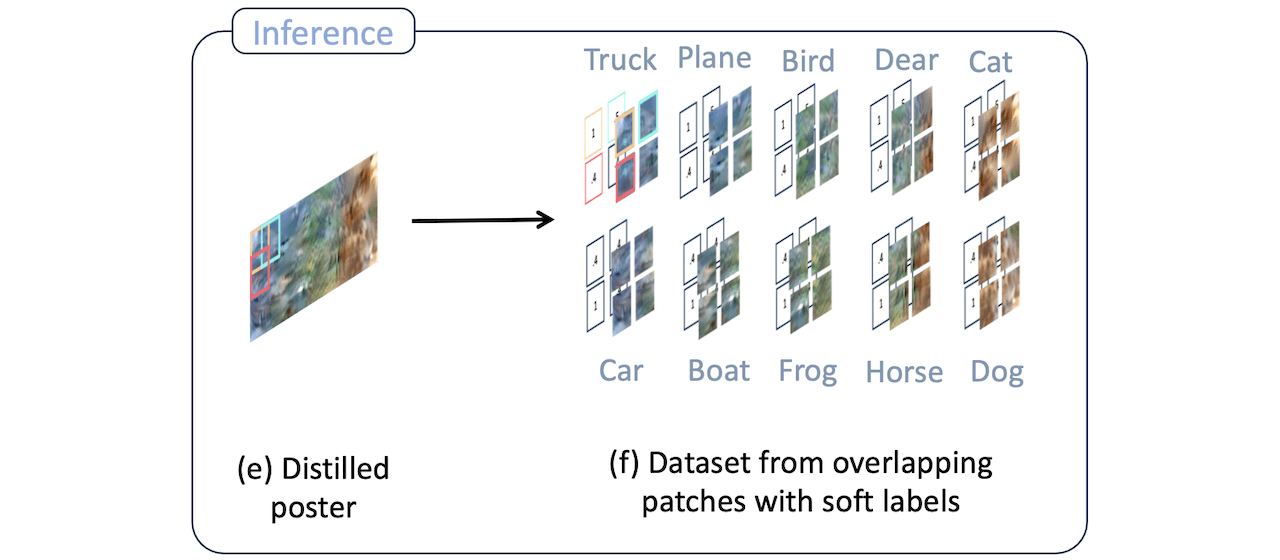
During inference, we extract overlapping patches and soft labels from the distilled poster and use them to train a downstream model (e-f)
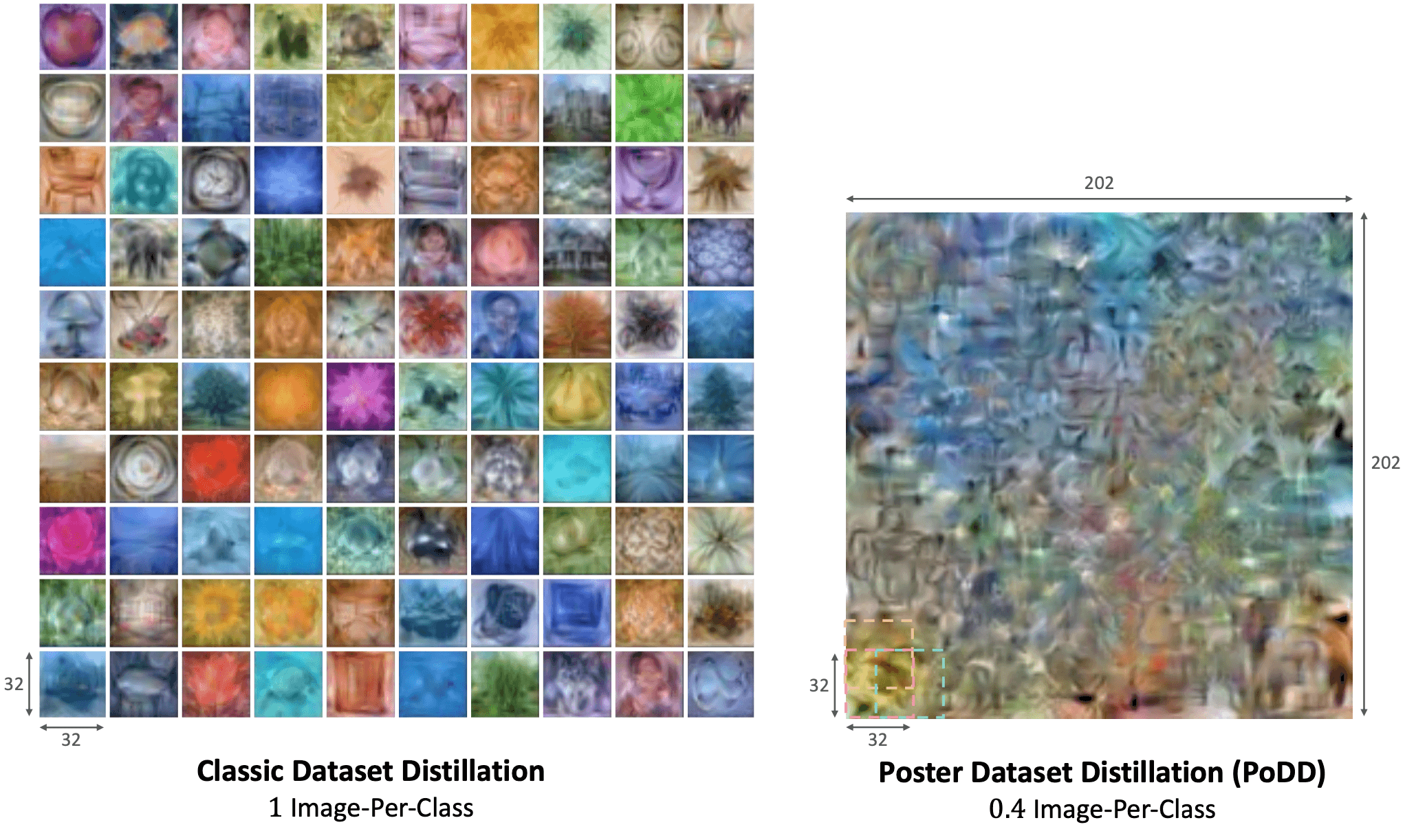
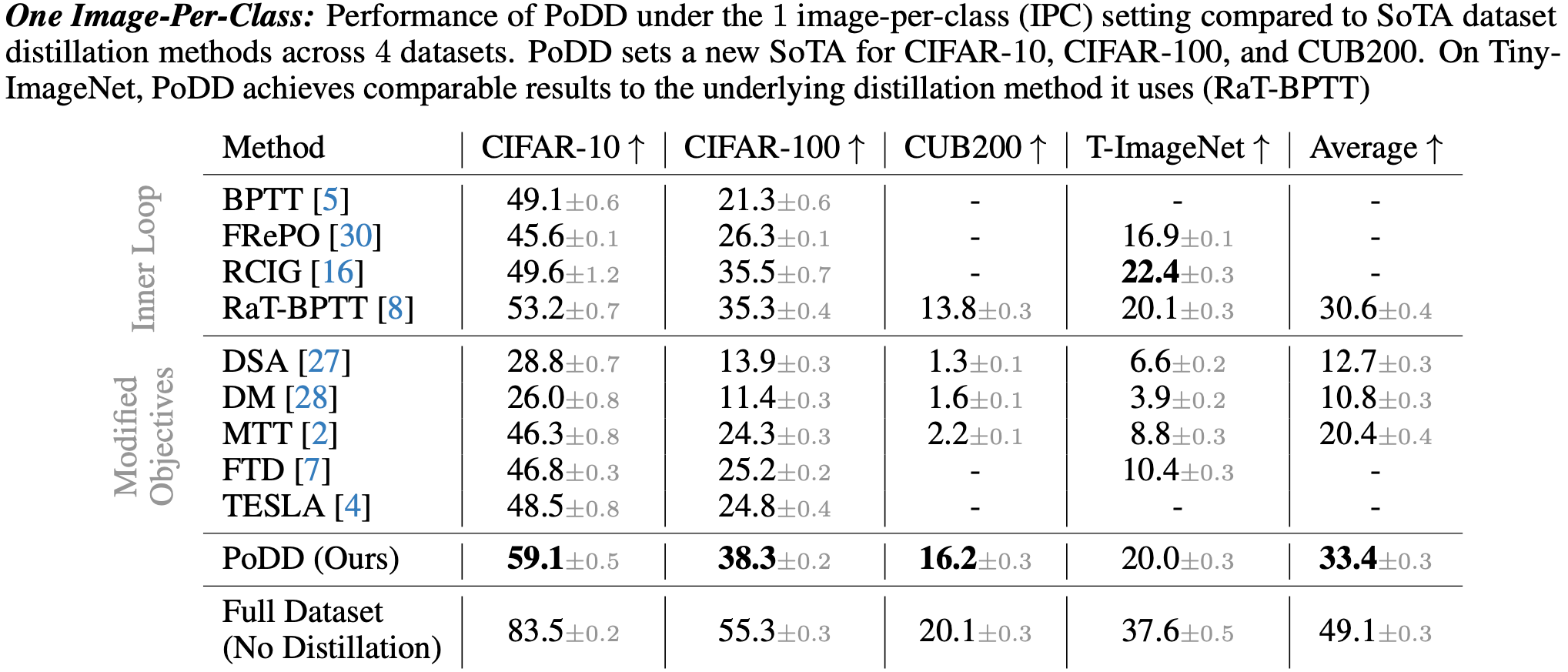
Results of 1 Image-Per-Class
Global and Local Semantics
We investigate whether PoDD can produce distilled posters that exhibit both local and global semantics. We found that in the case of 1 IPC, both local and global semantics are present, but are hard to detect. To further explore this idea, we tested a CIFAR-10 variant of PoDD where we use 10 IPC and distilled a poster per class. Each poster now represents a single class and overlapping patches are always from the same class. The method preserves the local semantics and shows multiple modalities from each class. Moreover, some of the posters also demonstrate global semantics, e.g., the planes have the sky on the top and the grass on the bottom.

BibTeX
@article{shuldistilling,
title={Distilling Datasets Into Less Than One Image},
author={Shul, Asaf and Horwitz, Eliahu and Hoshen, Yedid},
journal={Transactions on Machine Learning Research}
}