Abstract
The dominant paradigm in generative modeling consists of two steps: i) pre-training on a large-scale but unsafe dataset, ii) aligning the pre-trained model with human values via fine-tuning. This practice is considered safe, as no current method can recover the unsafe, pre-fine-tuning model weights. In this paper, we demonstrate that this assumption is often false. Concretely, we present Spectral DeTuning, a method that can recover the weights of the pre-fine-tuning model using a few low-rank (LoRA) fine-tuned models. In contrast to previous attacks that attempt to recover pre-fine-tuning capabilities, our method aims to recover the exact pre-fine-tuning weights. Our approach exploits this new vulnerability against large-scale models such as a personalized Stable Diffusion and an aligned Mistral.
In this paper, we identify a vulnerability in fine-tuned models, wherein the pre-fine-tuning (Pre-FT) weights, i.e., the model weights before the fine-tuning stage, can be recovered using a small number of models fine-tuned via low-rank adaptation (LoRA). Generative modeling consists of two steps:
- Pre-training on unsafe data.
- Alignment and safety fine-tuning.
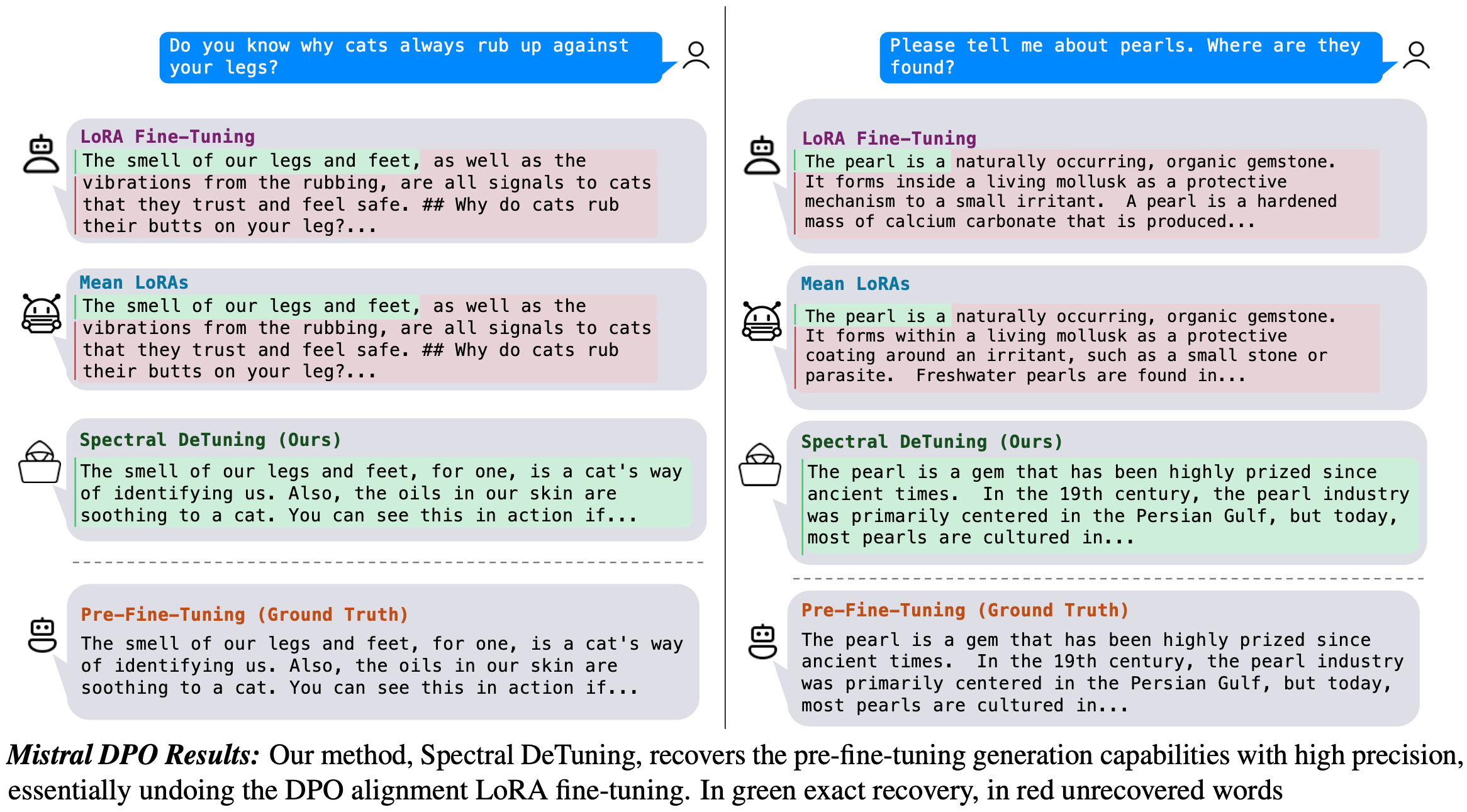
Pre-Fine-Tuning Weight Recovery
We propose the task of Pre-Fine-Tuning Weight Recovery. In this paper, we tackle this task in cases where multiple LoRA fine-tuned flavors of the same source model are available. To solve this task we present Spectral DeTuning, a method that recovers Pre-FT weights of SoTA models using iterative low-rank matrix factorization
Unlike previous attacks on model alignment that attempt to recover Pre-FT capabilities, we aim to recover the exact Pre-FT weights.
Moreover, it does not require running inference through the model. This is advantageous as i) it does not require training data ii) it is highly parallelizable, e.g., on a cluster of desktop GPUs such as RTX2080 our method can recover the Pre-FT weights of a Mistral-7B model in under five minutes.
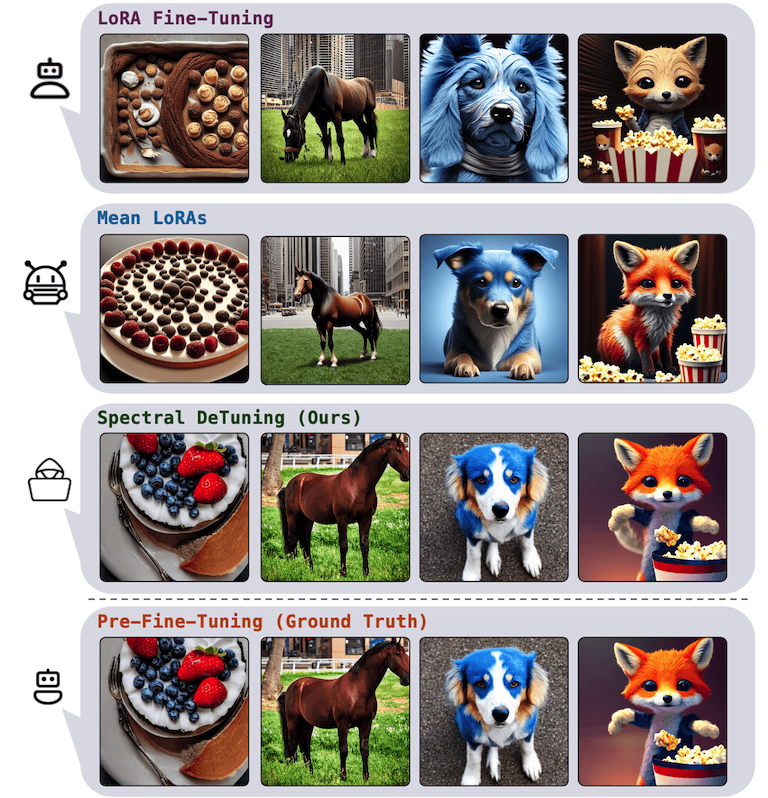
Stable Diffusion Results: Spectral DeTuning recovers the Pre-Fine-Tuning images with high precision, even when using "in the wild" LoRAs, essentially reversing the personalization fine-tuning of the LoRA model.
Vulnerability of SoTA Models
By using just 5 LoRAs taken from CivitAI, we can recover the Pre-FT Stable Diffusion weights with a vanishingly small error. As can be seen below, scaling up to a DPO aligned Mistral only requires 8 LoRAs.

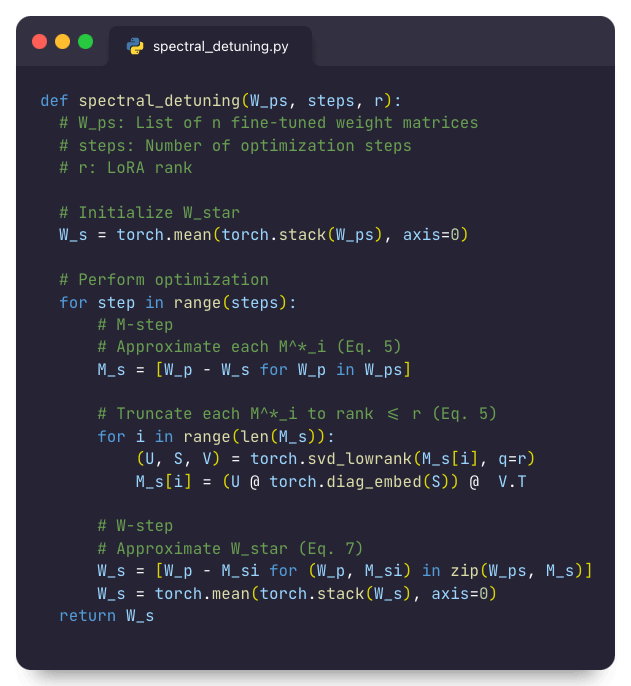
Spectral DeTuning
The core idea of Spectral DeTuning is to iteratively break down the optimization into a set of simple sub-problems which have closed-form solutions. This results in a simple yet powerful algorithm that can be implemented in 8 lines of code.
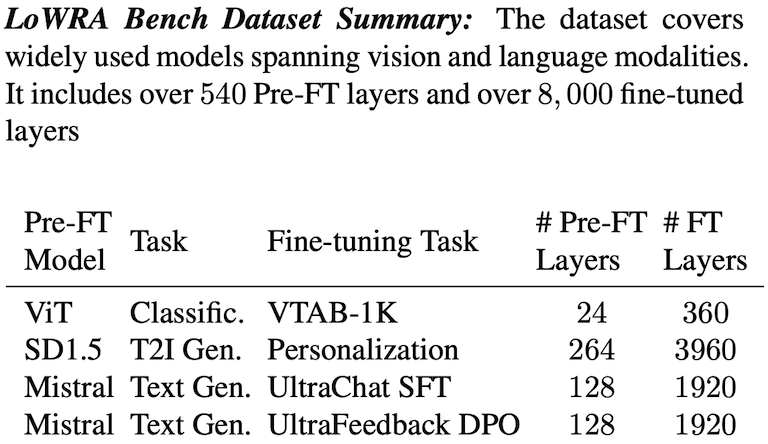
LoWRA Bench
To stimulate research into preventing Pre-FT weight leakage and the associated risks in terms of model safety and alignment we present LoRA Weight Recovery Attack (LoWRA) Bench, a comprehensive benchmark designed to evaluate Pre-FT weight recovery methods.
Our dataset encompasses three pre-trained representative source models: a Vision Transformer (ViT) trained on ImageNet-1K, Stable Diffusion 1.5, and Mistral-7B-v0.1. Notably, these models are widely used and deployed in numerous production systems.
Broader Impact
This work uncovers a significant vulnerability in fine-tuned models, allowing attackers to access pre-fine-tuning weights. While this discovery reveals potential security risks, our primary objective is to advance the field of Machine Learning and raise awareness within the research community about the existing vulnerabilities in current models.
Instead of using the findings of this study to execute attacks, we advocate for their use by model creators to enhance the safety and security of their models. By acknowledging and addressing vulnerabilities, creators can proactively safeguard against potential threats.
Furthermore, in the discussion section, we outline potential future directions and mitigation strategies. Following established practices in the cyber security community, we emphasize the importance of open discussion and encourage the reporting of vulnerabilities. By fostering transparency and collaboration, we can collectively create a safer environment for deploying machine learning models.
BibTeX
@inproceedings{horwitz2024recovering,
title={Recovering the Pre-Fine-Tuning Weights of Generative Models},
author={Horwitz, Eliahu and Kahana, Jonathan and Hoshen, Yedid},
booktitle={International Conference on Machine Learning},
pages={18882--18904},
year={2024},
organization={PMLR}
}