Abstract
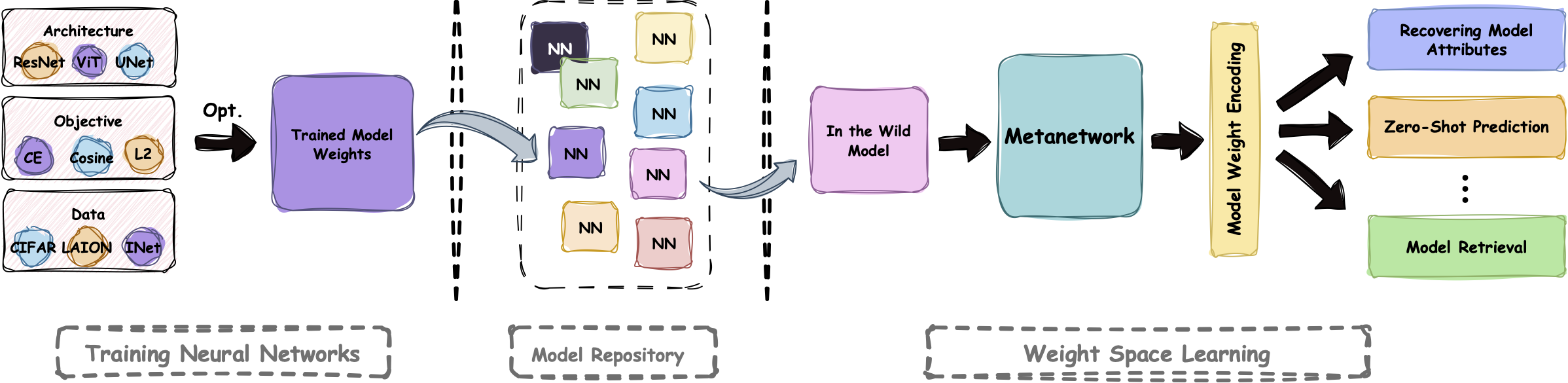
The increasing availability of public models begs the question: can we train neural networks that use other networks as input? Such models allow us to study different aspects of a given neural network, for example, determining the categories in a model's training dataset. However, machine learning on model weights is challenging as they often exhibit significant variation unrelated to the models' semantic properties (nuisance variation). Here, we identify a key property of real-world models: most public models belong to a small set of Model Trees, where all models within a tree are fine-tuned from a common ancestor (e.g., a foundation model). Importantly, we find that within each tree there is less nuisance variation between models. Concretely, while learning across Model Trees requires complex architectures, even a linear classifier trained on a single model layer often works within trees. While effective, these linear classifiers are computationally expensive, especially when dealing with larger models that have many parameters. To address this, we introduce Probing Experts (ProbeX), a theoretically motivated and lightweight method. Notably, ProbeX is the first probing method specifically designed to learn from the weights of a single hidden model layer. We demonstrate the effectiveness of ProbeX by predicting the categories in a model's training dataset based only on its weights. Excitingly, ProbeX can also map the weights of Stable Diffusion into a shared weight-language embedding space, enabling zero-shot model classification.
Learning within Model Trees

We conduct 4 motivating experiments that illustrate the benefits of learning within Model Trees. In each experiment, we train a linear classifier to predict the classes a ViT model was fine-tuned on. First, we show that learning within Model Trees is significantly simpler (a) by comparing a metanetwork trained on models from the same tree \(T\) with one trained on models from different trees \(F\). Next, we demonstrate positive transfer within the same tree (b) by showing that adding more models from the same tree improves the performance. Surprisingly, we observe negative transfer between Model Trees (c), where adding samples from other trees degrades performance on a single tree. Finally, we find that expert learning is preferable when learning from multiple trees (d), as a single shared metanetwork performs worse than an expert metanetwork per tree (MoE).
Largest Model Trees on Hugging Face

We show the 10 largest Model Trees on Hugging Face. Our insight is that learning an expert for each tree greatly simplifies weight-space learning. This is a practical setting as a few large Model Trees dominate the landscape.
Probing Experts (ProbeX)

Unlike conventional probing methods that operate only on inputs and outputs, our lightweight architecture scales weight-space learning to large models by probing hidden model layers. ProbeX begins by passing a set of learned probes, \(\mathbf{u}_1, \mathbf{u}_2, \ldots, \mathbf{u}_{r_U}\), through the input weight matrix \(X\). A projection matrix \(V\), shared between all probes, reduces the dimensionality of the probe responses, followed by a non-linear activation. Each probe response is then mapped to a probe encoding \(\mathbf{e}_l\) via a per-probe encoder matrix \(M_l\). We sum the probe encodings to obtain the final model encoding \(\mathbf{e}\), which the predictor head maps to the task output \(\mathbf{y}\).
Results
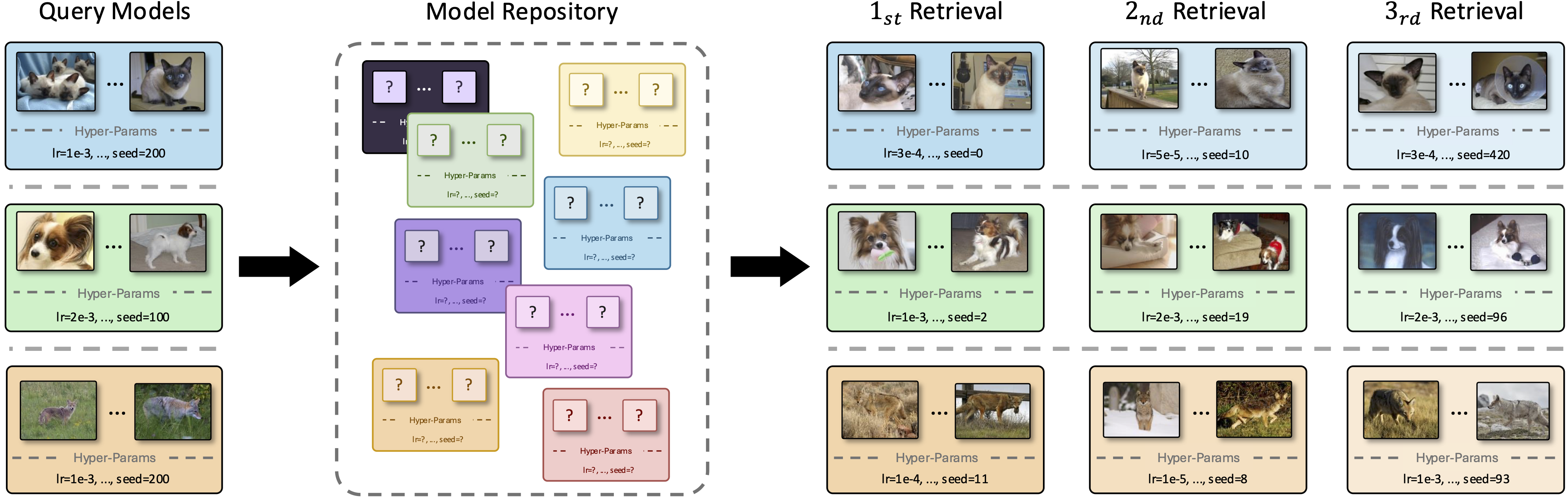
ProbeX achieves state-of-the-art results on the task of training category prediction, accurately identifying the specific classes within a model's training dataset. Excitingly, ProbeX can also align fine-tuned Stable Diffusion weights with language representations. This capability enables a new task: zero-shot model classification, where models are classified via a text prompt describing their training data. Using these aligned representations, ProbeX can also perform model retrieval.
BibTeX
@InProceedings{Horwitz_2025_CVPR,
author = {Horwitz, Eliahu and Cavia, Bar and Kahana, Jonathan and Hoshen, Yedid},
title = {Learning on Model Weights using Tree Experts},
booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)},
month = {June},
year = {2025},
pages = {20468-20478}
}