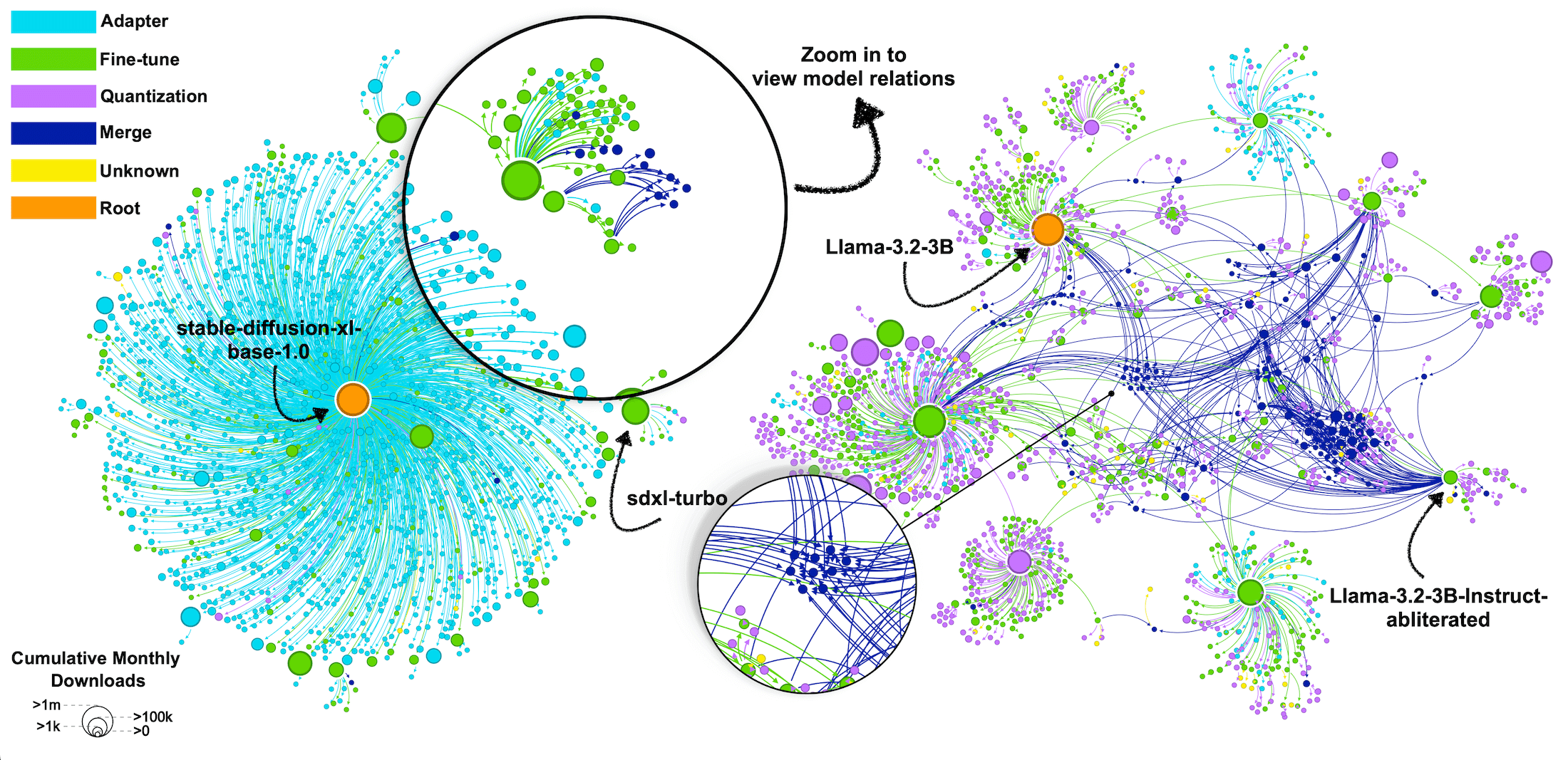
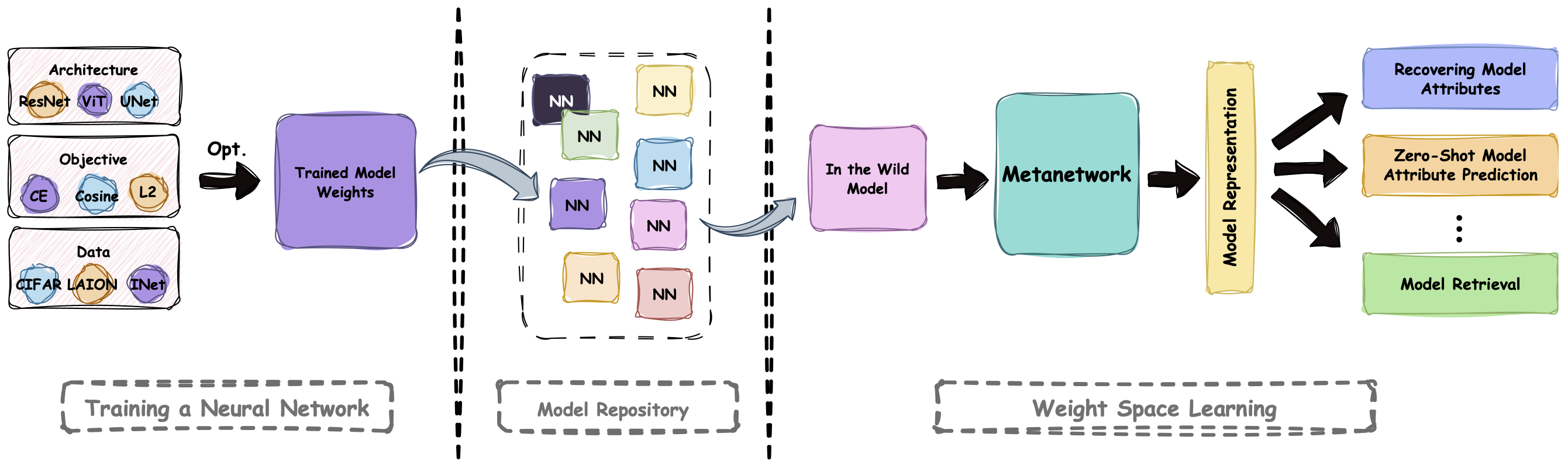
We Should Chart an Atlas of All the World's Models
NeurIPS 2025 - Position Paper

Pronounced eh • lee • yah • hoo, but you can call me Eli (eh • lee)
I am a Google PhD Fellow in Machine Learning and ML Foundations and a PhD student in Computer Science at the Hebrew University of Jerusalem, researching Weight Space Learning—treating neural networks as data and developing models that operate on neural networks. I am advised by Prof. Yedid Hoshen.
My research focuses on recovering neural network training trajectories and learning effective weight-space representations, ultimately enabling new ways to analyze, retrieve, and possibly generate models.
Before transitioning into research, I was a self-taught software developer, working across the tech stack at companies ranging from small startups to large corporations. This hands-on experience continues to shape my approach, bridging theoretical insights with real-world applications.